
理解Google Spanner(1):数据复制与分片
现在工作中有很多项目开始转到Google Spanner,虽然是很牛逼的分布式数据库,但由于太新了,并且是闭源的,网上几乎没有什么资料可查,为了更好地使用它,开始了Spanner漫长的学习之路,一个东西只有自己能教会别人,才代表自己真的会了,因此准备进行Google Spanner的一系列分享,这是第一篇,主要是讲Spanner的数据复制与分片,最后会提到实际应用中会遇到的热点问题以及解决方案。
本文主要是通过近期对分布式存储系统原理的学习以及平常工作中的一些实践去总结出的技术分享,由于对分布式数据库以及Spanner的理解有限,如果文中有错误的地方,希望大家能够指出。
一、Spanner 架构
先讲讲Spanner的架构,很概念很牛逼的东西,虽然乍眼一看不实用,但是让我们理解Spanner更进一步,特别是理解数据的复制、分片。
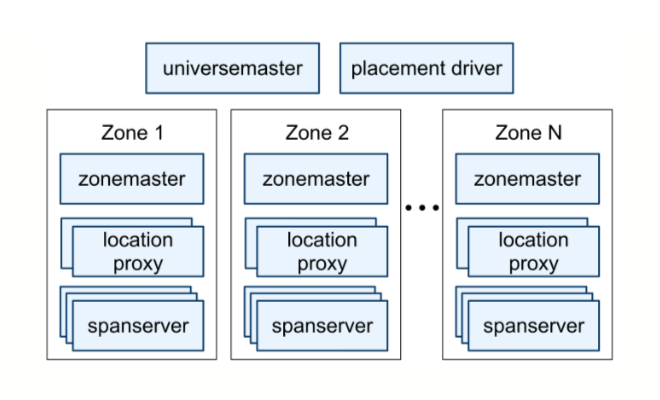
由于Spanner是个全球分布式数据库,因此Google给Spanner的部署取了一个很牛逼的名字:Universe,一套完整的Spanner部署为一个Universe。目前全球只有三个Universe,分别是Google为test、development、production三个环境所搭建的。每个Universe中有一个universe master和一个placement dirver。
universe master和placement driver所管理的单位是Zone,Zone不是逻辑概念,而是真正的物理隔离,每个数据中心有一个或多个Zone,universe master监控着每个Zone的状态信息。
每个Zone中有一个zone master、数个localtion proxy、上百到几千个不等的spanserver。zone master负责将数据分配给spanserver,数据都存储在spanserver,location proxy存储数据的位置信息,在客户端访问location server去定位它所需要的数据在哪些spanserver。
placement driver 会周期性地与spanserver通信,监控哪些数据需要迁移,去平衡负载或其他原因。(PS:白皮书上说是与spanserver通信,但每个Universe这么多spanserver,通信量非常巨大,感觉应该是与zone master通信才是,这一点相当反直觉)
二、数据分片
虽然我标题写着“数据复制与分片”,但是我想先讲分片,再讲复制,那么写标题纯粹是因为看着更顺眼,请不要在意细节。
假设你在Spanner创建了一个Regional Instance并且配置了3个node,也就是说Spanner千千万万个spanserver中,有3个是为你启动的,spanserver并不是物理机,而是虚拟机,只是一个容器集群中的一个Pod或Container。(以下将会把spanserver称为node,因为大家更熟悉这个术语)
基于负载和数据量的分片
想象你有一张名为“Users”的表,保存着所有注册用户的信息,这张表有10万条数据,为了简单,假设你的整个应用只有Users表,没有其他数据存在Spanner。
为了最大化利用分布式系统的资源,并且使你的数据库可以轻松通过scale out获得处理能力的提升,Spanner一定会将Users表分成若干份,以一定规则分配给3个node。你一定注意到了,这里并不是按照node数量分成3份,而是若干份,每份称为一个split,将表拆分成若干个split的行为叫做分片(sharding)。
split之内有顺序,按主键(primary key)排序,是一组主键连续的记录,但是split之间是没有顺序保证的,也就是下图这样:
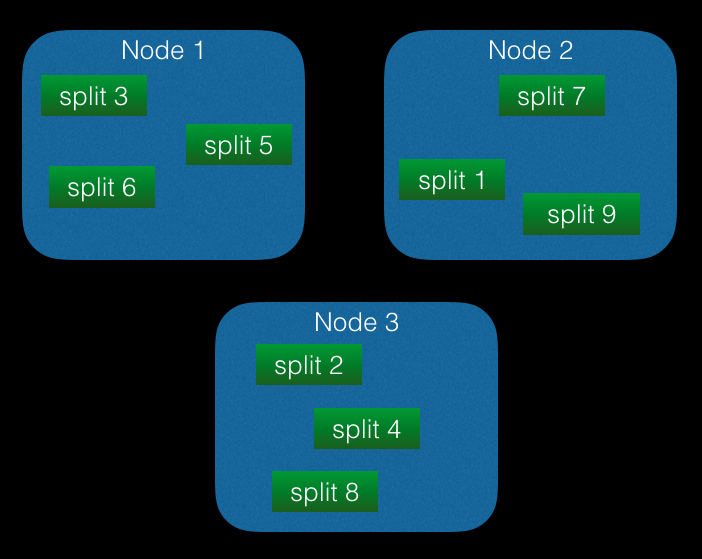
split对于一张表来说,是最小的数据分配(assign)单位,如果要将表中的某些数据从一个node转移到另一个node,一定是将整个split转移。在第一节“Spanner 架构”中有讲到,有一个placement driver会周期性地与node通讯,获得其负载情况,如果检查到有的split被读写频繁、负载高,那么会在3个node间转移split,平衡每个node的负载,或者是将split再拆分为更小的split,在node间转移以平衡负载。拆分split不止是出于负载考虑,还可能是因为split数据量增大,split大小达到一定阈值后,也会被拆分。
想象上图中放置在node 2的split 1被读写非常频繁,而其他8个split都比较空闲,node负载非常不均匀,聪明的Spanner觉得应该将split 1拆分并分配到其他空闲node,假设split 1保存着user_id为1到100的User,它并不是将user_id的范围平均分配,而是根据负载去拆分,比如user_id为1到10的行(row)被访问频繁,而11到100的数据几乎没有什么访问,那么它可能会将split 1 sharding为{1~3} {4~7} {8~100},而不是智障地sharding为{1~33} {34~66} {67~100}。
分片的边界(split boundary)
Spanner支持一种称为Interleave的结构,也就是父子表,子表的主键是多个字段复合的主键(composite primary key),它的前缀是父表的主键,子表的行被嵌套在父表的行中,Spanner保证了子表的行与其对应的父表行是在物理上存储得尽量接近的(co-locate)。
分片是以最外层父表的行为边界,也就是只有最上层的行,才能作为分片边界,借一张Google的官方图片说明一下:
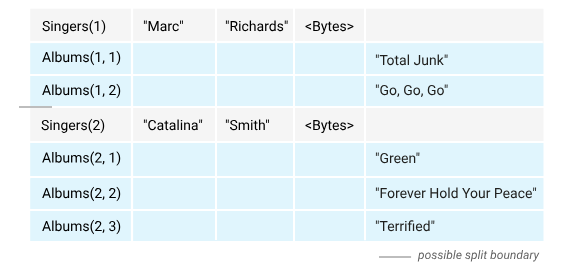
Singers是父表,Albums是子表(is interleaved in Singers),图中灰色那条线是被允许的分片边界,分片边界只能在Singers表的行之间移动,而不能在子表中移动,子表将永远和父表分片到一起,不能单独存在。 因此,如果子表产生热点,那么Spanner将不能通过重新分片的形式去平衡负载。因此,如果将Albums作为Singers的子表,那么如果有一个歌手非常火,他的所有专辑的总访问量占了全网20%的流量,那么就意味着有一个split将永远承受这20%的访问,无法拆分。因此,不要随意使用父子表,如果要使用,一定要知道,你为什么要使用,开发人员永远要忍住——不要过度设计。
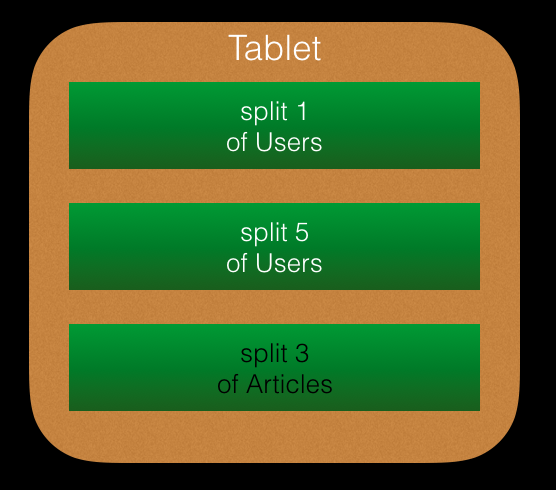
Tablet
在spanserver中有一个被称为Tablet的结构,Google BigTable中也有Tablet的概念,是一组连续主键的记录的集合,因此更像是Spanner中的split,Spanner的Tablet与BigTable中的有一些不同之处,Spanner的Tablet是一组split的集合,他们物理存储在相近的位置,split之内是按主键有序的(这个在前面讲到过),而Tablet中的数个split之间,他们的主键并不要求有序,也就是说一个Tablet甚至可能由来自多个不同表的split组成,Spanner会将频繁一起访问的数据放在同一个Tablet,使它们co-locate。
比如有Users和Articles两个表,并且都是顶层表,不存在Interleave关系,某一个Tablet可能会如下图:
数据如何被移动
当数据需要被移动时,不是以split为单位,数据移动的单位是目录(direcotory),目录就是顶层表的一行,因此,如果一个顶层表之下嵌套的子表数据量太大,数据移动的负担就越大,目前一个目录最大支持4GB,如果多于4GB,这个目录将会被拆分成片段(fragement),这可能会失去Interleave的co-locate保证,不过再想想,一个子表这么大?那这可能不应该设计为子表。
三、数据复制(Replication)
spanserver层的复制
当你的Regional Spanner Instance配置了3个node时,其实你得到了9个node,对于Regional Instance,目前固定是3个副本(replica),因此这是一个买一送二的操作。每个副本都将保存在不同的Zone,由于Zone是物理分离的,因此3个副本都做到了物理分离。
每个tablet之上都运行着一个Paxos状态机,状态机的元数据和Paxos日志都存到它对应的tablet中。因此每个tablet都有一个副本,tablet中的所有数据都共享同一份副本配置。Paxos是一个牛逼的分布式一致性算法,简单来说就是保证副本之间达成一致的算法,我们有3个副本,该听谁的,数据应该如何,Paxos说了算,它保证数据的最终一致性。
Spanner的Paxos实现支持长寿领导者(long-lived leader),默认是10秒,10秒过后重选leader。获得leader资格的叫做主副本(master replica),其他两个叫做从副本(slave replica)。
Spanner采用的是同步复制(synchronously-replicated),对于所有写入,主副本将改动的日志(log)同步更新到两个从副本,当从副本表示同步完成后,主副本才能向客户端返回成功的状态,因此一旦客户端接收到写入完成,那么再次访问任何一个副本进行读取,都能得到最新的数据。
下面是一张Spanner白皮书中的图片,可以看到tablet、Paxos、replica,(图中有一些文中没有提到的概念可以暂时忽略,它们涉及到事务,在以后的文章中会讲到):
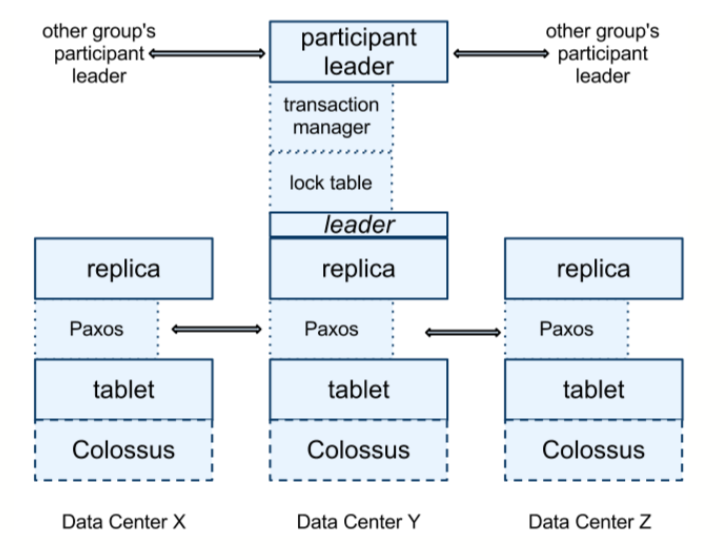
基于文件系统的复制
Google在每个数据中心(Data Center)都运行着一套Colossus,从上图中可以看到。Colossus是第二代GFS(Google File System),如果对GFS有了解的话,应该知道GFS本身就是一套分布式文件存储系统,因此它也实现了数据的复制,它会将数据分为多个chunck,每个chunck都会有3个副本,这样说来,理论上存在Spanner的数据可能会有3*3=9个副本,但是9副本实在太浪费了,因此实际上Spanner和GFS结合起来可能做了特殊的处理,减少了副本数,不过白皮书也没有说明这一点,大家可以发挥想象。
四、分片(split)与热点(Hotspot)
热点(Hotspot)是由于读写倾斜造成的某个server负载高,而其他server相对空闲的情况,根据木桶理论,最短的那块板决定了桶里能装多少水,如果在稳定状态下,某个server成为热点,而其他server空闲,那么最繁忙的server就成为系统吞吐量的瓶颈。为了最大化吞吐量,我们需要尽量避免热点的产生。
> 热点(Hotspot)的坏处是导致吞吐量上不去。
1. 以单调递增(Monotonically Increasing)的值作为主键
如果主键单调递增,那么每一次插入新的行都是在整张表的末尾,也就是这个写入请求一定会落在整张表的最后一个split,那么最后一个split就会成为热点,Spanner无法通过重新分片的方式去平衡负载,因为写入的热点永远在最后一个split,只要世界上存在“最后一个split”,就存在热点,这是一个哲学问题…
因此,我们要避免的不是以什么样的值作为主键,而是要避免你的数据永远都在同一个split插入,主键是一种途径,而不是目的。单调递增的主键会引起这个问题因此尽量不要使用。
是不是一定不能使用单调递增的值作为主键?
并不是。一切设计看业务,规则只是参考。如果使用单调递增主键对业务有很大帮助,并且表的插入相对来说非常少,是可以考虑使用的,热点就是资源使用的倾斜,只消耗资源很少一部分的情况下是不会造成倾斜的。
2. 如何正确使用父子表(Interleave)
Interleave可以使Spanner保证子表行(rows of child)与所属父表行(their parent row)物理邻近地存储(co-locate),Ressi是Spanner底层存储使用的数据结构,它使用LSM-tree存储数据,引用一段来自Spanner白皮书的说明:
> Ressi supports Spanner’s INTERLEAVE IN PARENT directive by storing rows of child tables in the same (or nearby) blocks as their parent rows.
Spanner会将子表行存在与父表行相同或相邻的数据块(block)中<
如果同一条SQL语句同时涉及两者,比如join,则Interleave是一个很好的加速,避免了多台server之间的join,但是如果是分别在两条SQL中访问父表行与其对应的子表行,那么Interleave并没有什么特别的优势。并且由于Spanner使用了LSM-tree,那update父表或子表时,可能会将某些数据复制一份到最新写入的数据中以保证co-locate,这只是一个猜测,Spanner没有提到具体的实现方式,但是一定会有某些设计去保证co-locate,因此如果在不需要的情况下依旧使用Interleave,会造成一些额外开销。
并且,Spanner进行分片的边界只能是顶层表的行,而不能对Interleave子表进行分片,所以当子表产生热点时,意味着Spanner对这个热点束手无策。
如果父表和子表存储的都是同一个数据,比如父表是notification, 子表是email_notification,sms_notification,每个notification只可能是email和sms中的一种,也就是一行父表只可能对应一行子表,并且还是描述相同的实体,这种情况合并为同一个表比较好,比Interleave更快也更简单。
我赞同的原则是:在增加复杂度没有明显收益的时候,就不要增加复杂度,选择更简单、灵活的方式,如果你不知道一个场景为什么要使用Interleave,你找不到它特别好的理由,就不要使用,就不要使用,就不要使用!重要的事说三遍。Spanner是一个很新的数据库,Interleave是很新的特性,但它不是银弹,它有优势也有限制,你在使用它之前,需要知道你为什么使用它,好处在哪里坏处在哪里,如果不知道,就不要使用,make things simple。
如果经常以父表主键作为条件查询子表行,同样不是使用Interleave的合理理由,子表依旧可以提升为顶层表,主键可以选择父表的primary key+自己的key为联合主键,比如Users表和User_photos表不一定需要Interleave,它们都可以设计为顶层表,Users表主键为(user_id),User_photos表主键为(user_id,photo_id),效果是一样的,并且不需要Interleave。
3. 索引也是表,也可能产生热点
Spanner对索引的实现也是一张表,因此如果最左前缀索引字段是单调递增的,也会造成每次插入都在最后一个split。这里可以通过为索引增加一个最左前缀shard_id来解决,shard_id可以是指定字段的hash值,并对某个整数取余,比如100,最后得出0~99的区间,这样数据的分配就会相对均匀而不会每次都插入到同一个split。
4. 如果同一个主键前缀的写入/读取频率高,也会产生热点
比如淘宝有一个product_sales表,每个商品卖出一件都会被记录,主键为(product_id, buyer_id),大多数商品可能一个月累积起来也只有几十条销量,而爆款商品,特别是在促销时,可能每秒都会售出几十上百个,此时大量product_id相同的数据要插入,一定都是插入在特定的少数几个split,此时相应的node会成为热点,就变成了大商家一做活动就影响了小商家的正常经营,这种情况可以使用shard_id作为主键的最左前缀,由于单个客户的下单量不会太高,因此可以使用buyer_id字段去计算shard_id,这样也保证了每个客户所购买的商品都在相同或相邻的split,查询时可以访问更少的node,使用户查看自己购买列表时可以更快获取数据。
5. 结语
其实热点、性能都不是很可怕的问题,它们都可以被优化,最可怕的是——过度设计,过度设计往往意味着将设计变得复杂,越复杂的架构,就越难修改越难优化,它会让本来很简单的问题变得难以优化,成本太高。技术是为商业服务,低成本换高利润才是技术应该做的,而不是追求完美,舍本求末。如果没有理由让它变得复杂,那就先让设计变得简单。
五、学习路径与参考资料
由于Spanner没有开源,因此学习基本靠少量文档、白皮书,大量的通用的存储系统、分布式系统原理,我的学习路径与重点资料如下,希望对想要理解Spanner或其他分布式系统的同学有帮助:
Step 1. 学习数据库原理
首先可以通过学堂在线的一些高校的数据库原理课程,配合经典的《数据库系统概念》先理解一些理论。
Step 2. 学习已实现的单机数据库
刚开始学习的原理其实还是会很懵逼,不知道数据库在现实中到底如何应用这些原理去真正做出一个运转的数据库。MySQL是应用最广的开源关系型数据库,因此优秀的资料非常多,可以通过理解MySQL去理解数据库原理的实现,在这里顺便推荐一个非常通俗易懂的国内开发者写的资料《MySQL是怎样运行的:从根儿上理解MySQL》
Step 3. 学习分布式数据库原理
理解了数据库原理后,就理解了单机数据库的运作方式,可以开始学习分布式数据库了,这里推荐《数据密集型应用系统设计》
Step 4. 学习已实现的分布式数据库
在对分布式数据库概念有一定理解的情况下,可以开始阅读一些已实现的分布式数据库的技术细节,比如开源的TiDB、TiKV,以及Google BigTable,大概了解一些分布式数据库的样子。
Step 5. 阅读Spanner文档、白皮书
在理解了单机数据库原理、分布式数据库原理并且对其他分布式系统有一定的了解后,可以开始阅读Spanner文档和白皮书去理解Spanner的实现。 Spanner白皮书:
Google Spanner: Becoming a SQL System
Google Spanner: Google’s Globally-Distributed Database
网上还有一些参考资料,每份资料都是加入了作者自己的理解, 不同文章中对同一个概念和实现可能有不同理解,我在结合英文原版白皮书看的时候,和他们的理解也不一定是一样的,因此资料只作为参考。(并且网上的参考资料中也有少数错误,所以一定要看英文原版白皮书)