
理解Google Spanner(2):数据是如何存储的

阅读本文之前,最好已经阅读过Spanner官方文档。 本文适合以下两类人: A. 如果你读完官方文档完全没能举一反三,还是一头雾水,不知道使用Spanner的正确姿势是什么,以及为什么这些姿势比较正确。那你就可以读一下这篇文章,一定会对你有帮助。 B. 如果你对数据库原理及其实现有一定理解,你读完官方文档已经举一反三大概猜测到了它的实现原理,大神,还是请你读一下这篇文章,交流一下我们理解不一致的地方。
重要的话再说一遍:阅读本文之前,最好已经阅读过Spanner官方文档,带着问题来读这篇文章,收获会更多一些。
(如果你想对Spanner的基本架构有一个概览,可以读一读上一篇:理解Google Spanner(1):数据复制与分片)
本文会讲什么
要理解Spanner中的数据是如何被存储、组织的,只有三个关键词:
- Key-Value数据库
- LSM-Tree
- PAX 行列混存
一、存储形式:Key-Value数据库
Key-Value数据库怎么组织数据
首先,Spanner不是关系型数据库,也不是NoSQL,它被称为NewSQL。Spanner的本质是Key-Value数据库,在Spanner底层,是没有Schema的,任何一行数据都会被转换为一个或多个Key-Value对存储。
对于基于Key-Value的NewSQL数据库,面向用户这一层是可以定义Schema的,它怎么将Schema转换为底层的Key-Value存呢?也就是说,怎么为数据构建一个key呢?
首先,我们得保证每一个Key在数据库中全局唯一,如果不唯一,可能会出现X表的某条数据覆盖了Y表的某条数据这种情况。
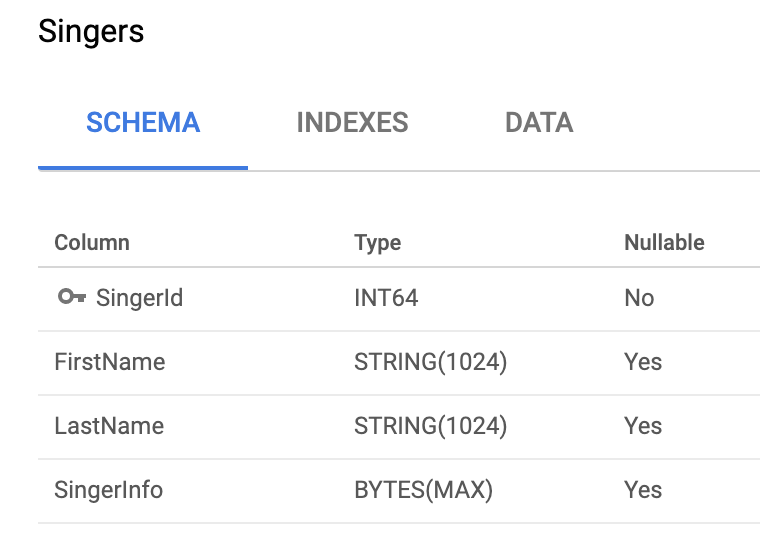
以下图中的Singers表为例,我们可以为每个表都分配一个唯一id,比如Singer表的id为singers,在表中,主键(Primary Key)一定是唯一的,那么将他们拼起来就是singers_primarykey1,那么这行数据是这样存的:
singers_1 : (1, "Jay", "Zhou", "台湾歌手")
 因此,对于每一行数据,我们都可以使用
因此,对于每一行数据,我们都可以使用(table_id+ primary key)组成为Key定位到它。表就是Key-Value对的集合。
那如果我们需要二级索引(Secondary Index)呢?我们希望通过FirstName查找歌手,但是并没有用FirstName组成的Key,因此我们需要为每行记录构建由FirstName组成的Key,使得这些Key可以查找到那行记录。注意,我们前面说到表就是Key-Value对的集合,索引也是Key-Value对的集合,因此,索引也是表,因此索引也有唯一的table_id,比如firstname。因此这个Key的format为 firstname_{FirstName},而对应的value就是符合条件的记录的Primary key:
firstname_Jay : (1)
可以使用FirstName查到这行记录的Primary Key为1,然后再使用Primary Key去数据表中查找到完整记录。
不过,由于Key必须保证唯一,因此这个索引是唯一索引(Unique Index),只可能有一个Singer的FirstName为”Jay”,否则多个Column的值会被互相覆盖。
如果要实现非唯一索引(Non-unique Index),该怎么做呢?简单,将Primary Key从Value中移出来也作为Key的一部分就好了:
firstname_Jay_1 : null
fristname_Jay_99 : null
索引中的Value统一为Null,Primary Key直接放在了Key中,代表id为1和99的Singer都叫”Jay”。
等等,上面这样设计数据表(Table)和索引(Index)的Key,好像不能保证唯一性了,万一有一个数据表也叫firstname呢?有道理,所以我们需要一个前缀区分数据表和索引,我们可以使数据表的前缀为table,索引的前缀为index。
那么数据表的结构应该如下:
table_singers_1 : (1, "Jay", "Zhou", "台湾歌手")
唯一索引的结构如下:
index_firstname_Jay : (1)
非唯一索引的结构如下:
index_fristname_Jay_1 : null
Perfect Done.
数据如何排序
理解了如何使用Key-Value的形式组织数据,就理解了Spanner是如何组织数据,不论是表还是索引,都是表,那么下一个问题:表中的数据如何排序呢? 首先,数据是根据Key排序的,从小到大升序排列。 Key是如何排序的? 首先,对于同一个表的数据,前缀(Prefix)应该是相同的,那么它们会根据接在后面的主键排序,如果是数字,则按数字从小到大排列,如果是字符串,则使用字典序(Lexicographical Order),字典序是依次对比字符的,先对比左边第一个字符,如果相同,再对比第二个字符,直到分出大小为止。因此,排序结果和字符串长短没有关系,没有关系,没有关系! For example,对于下面三个字符串,正确排序应该如下: 1. “aaa” 1. “b” 1. “cc”
看到这里你可能有一个问题:主键是数字也会被拼接到Key中,不就变成了一个字符串吗,不也应该按照字符串的字典顺序排列吗? 答:前面讲的将Primary Key拼接到Key,并不是说一定会拼接成一个字符串,实际上在底层,都是一个个二进制位,一个个Bit,上面说的将Key拼成字符串只是为了好理解。
从数据的组织理解Interleave
利用预读
由于是根据Key排序,所以前缀相同的Key,一定会排列在一起,这里就和Spanner中有Interleave结构有关系了。
父表的Primary Key是子表的Primary Key的前缀,因此子表的rows会紧跟着排在父表后面。那么重点来了:
子表行会紧跟父表行存储,也就是会存在同一页或者相邻页(这在白皮书中也有说到),因此如果访问父表行的同时要访问相应的子表行,效率会有提升,因为每次Spanner会从硬盘读出一页或多页数据(预读),你要访问的子表行已经在内存中,这种情况下,速度会比不使用Interleave更快。
但是由于它是利用预读,如果你要访问的子表行离父表行太远,预读也会失效,比如父表行对应的子表行有1万行,100MB,而你要访问的子表行距离对应的父表行有8000行,也就是大概距离80MB的数据,那么Spanner可能不会进行这么远的预读…也就是说,对于子表行太多的情况,Interleave的优势也被削弱了,反而使数据分片变得困难,增加了热点(HotSpot)的可能,因此这种情况下是否应该使用Interleave值得考虑。
避免多节点数据传输
Spanner是计算靠近存储的,也就是每个节点不止存储着数据,还分配有计算资源,Spanner对Interleave提供了父表行与对应子表行一定存储在同一个节点的保证,因此有的计算可以在相同的node完成,而不需要将数据传输到其他node完成计算。比如对于一个Join语句,如果需要被Join的数据就存储在本节点,那么就可以直接在节点中完成join,而不需要进行distributed join,减少网络传输,提高Join效率。 但是如果父表和子表很少甚至完全不会涉及到一起参与计算,那么Interleave的这个优势就利用不上,此时是否还坚持使用Interleave也值得考虑了。
二、组织方式:LSM-Tree
对于传统的关系型数据库,一般使用B+ Tree的结构组织表,查询非常高效。(如果你还不理解传统的索引结构,可以先看看理解数据库(1):数据组织方式与索引,请一定先对B+ Tree有一定了解,否则不容易理解下面的LSM-Tree) 但是B+ Tree对于写入则不那么友好,因此每次写入都需要插入到合适的位置,那么就可能涉及到页分裂,且每次写入时插入的位置不同,那么写入打在磁盘上都是随机的,而随机写比顺序写要慢了几个数量级。于是出现了一种新的数据组织方式:LSM-Tree,全称为Log Structured Merge Tree。
写
LSM-Tree是一种追加写(Append only)的数据组织方式,LSM-Tree分为多个数据段,每个更新的数据段相对于更旧的数据段,都是追加的,不会修改旧数据段,这些数据段称为SSTable(Sorted String Table)。 SSTable是内部有序的,并且Key唯一,也就是说同一个SSTable中不是追加写,是in-place update。刚刚不是说希望能将随机写都变为顺序写吗,为什么SSTable可以随机写? 因为写入是直接到内存的,LSM-Tree在内存中划分了两块区域,一块是MemTable,新写入的数据都存在这里,在内存中进行随机写与排序的速度都是非常快的,另一块区域是Immutable Table,当MemTable中的数据量达到一定阈值后,将会把MemTable转化为Immutable Table,Immutable Table是不可被修改的,它将在稍后被刷入磁盘。 Immutable Table被刷入磁盘后成为一个独立的SSTable,磁盘中的SSTable分为多个层级,新鲜数据都被刷到Level 0层,每一层可能有多个SSTable,当本层的数据达到一定阈值后,将会被合并刷入Level 1层,以此类推。由于SSTable本身有序,因此在合并时只需要使用归并排序,那么合并后的下层SSTable也是能够保证顺序的。合并SSTable有助于减少冗余数据、增加读写效率。
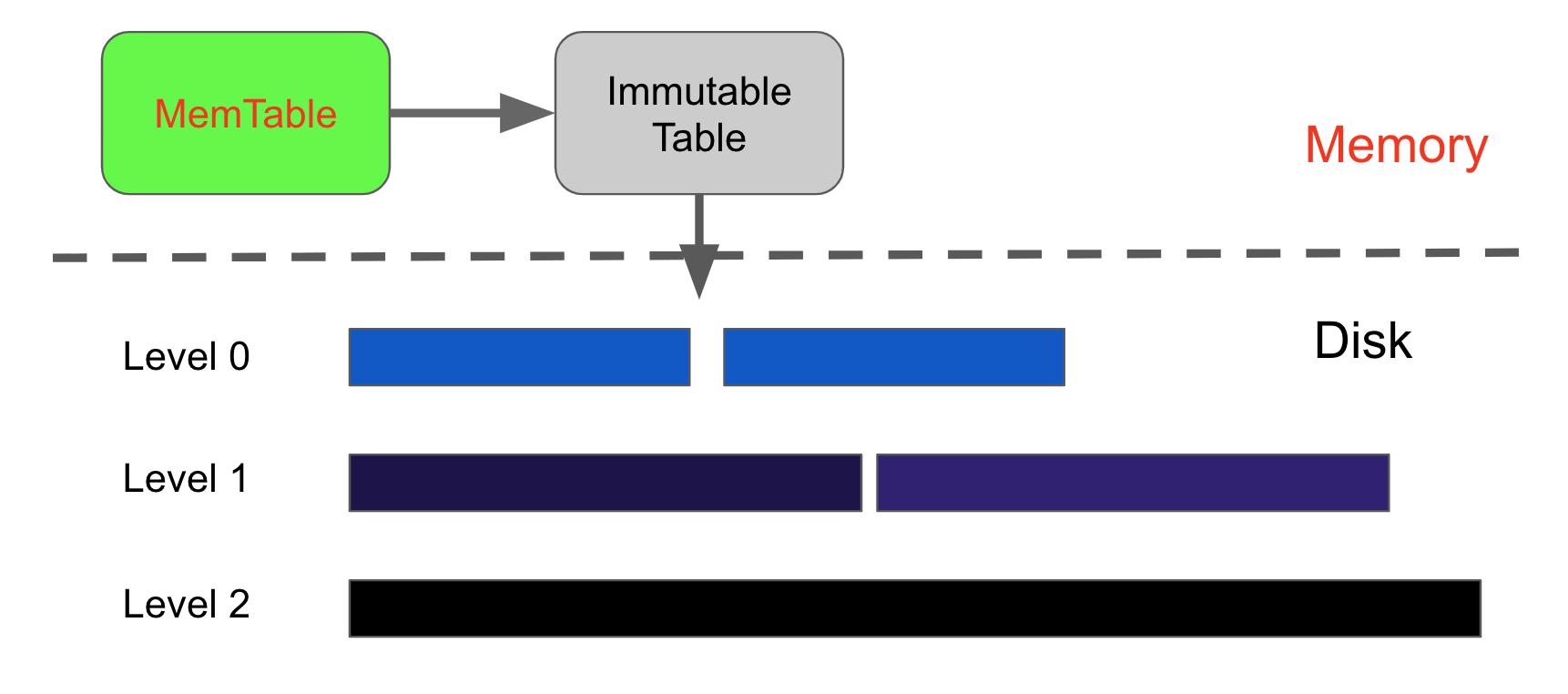
Spanner会周期性地对SSTable进行压缩合并,可以从后台CPU utilization监控看到,红色为Low Priority System Task,也就是对数据进行压缩所消耗的CPU,对数据进行压缩是低优先级的任务,如果有读写进来,压缩会让出它们所需要的CPU,但是如果读写一直抢占CPU,导致数据的压缩无限推迟,就会造成读性能下降,因为冗余数据太多,由于读性能下降,就会导致写性能也下降,因为数据写入前也需要进行读取,比如修改了Singer的FirstName,则需要将数据重新写一份到MemTable,需要先查找到修改前的版本,然后将它的值复制到MemTable写入。因此,对于更新频繁的表,如果只是集中在一两个小字段,某些空间占用达到几KB甚至更多的大字段几乎不会更新,理论上进行拆表会提高写入效率,将不更新的大字段放入另一个表避免了每次写入都重新复制一份值。
 为了保证Spanner更低的Read/Write latency,应该尽量为数据压缩合并提供足够的CPU。
为了保证Spanner更低的Read/Write latency,应该尽量为数据压缩合并提供足够的CPU。
读
虽然LSM-Tree的顺序写入方式提高了数据库的写吞吐量,但是相比B+ Tree,在读的性能上却有一些损耗,因为每次查找指定Key,都需要从内存开始,然后依次往下查找,直到找到为止,因此相比B+ Tree,就可能有更多的读损耗。
为了尽量避免读取不必要的数据,每个(或者每层)SSTable都有一个布隆过滤器(Bloom Filter),对每个要查找的Key,进行hash后,如果未命中布隆过滤器,则说明这个Key在这个SSTable中绝对不存在,则避免了无效的读取,节省了IO。如果命中了布隆过滤器,则说明这个Key可能存在在这个SSTable中,开始对这个SSTable进行查找。
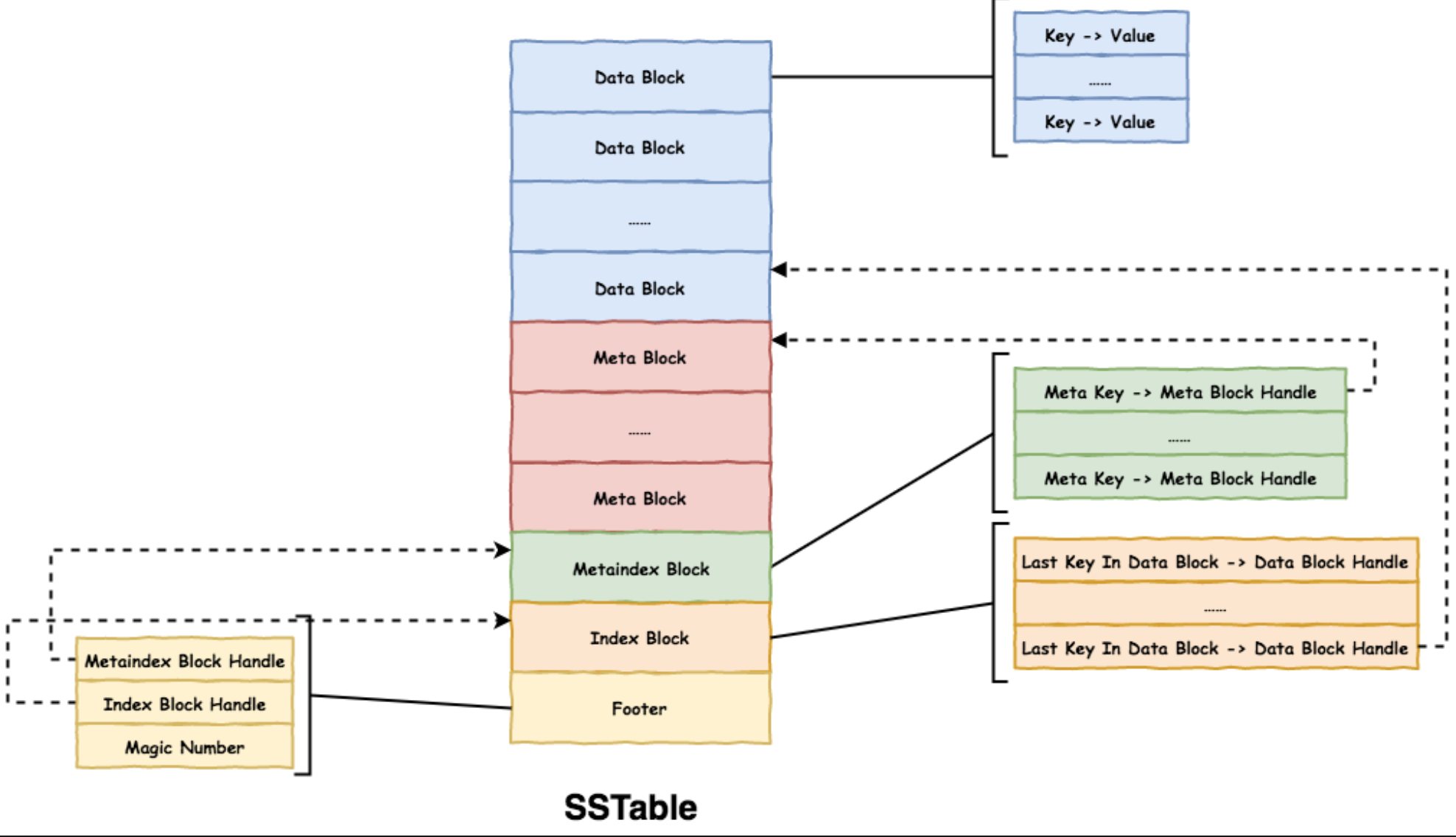
下图为Level DB中的SSTable结构,每个Table有多个Data Block,每个Block有固定大小,可能是64KB,Index Block是对Data Block的索引,保存着每个DataBlock的最后一个Key,因此先根据Index Block确定key处于哪个Data Block,再读取对应的Data Block,查找Key的值。
三、块(Block)结构:PAX 行列混存
每个SSTable中都有数个数据块(Data Block),每个数据块都会被一起刷入磁盘,为一页(Page),在Spanner之前,页中的数据组织一般有两种方式:行存(NSM)和列存(DSM)。
行存是将每一行的数据依次写入Block中,如果我们SELECT *一次性查出所有列,或者一次查出大多数列,则行存非常高效,因为从磁盘的一次读取,就能把这个record的所有列都查出来。但是如果我们每次只查一列或者少数列,就会读入大量无用的数据,无用的数据比有用的数据多很多倍,因此容易造成内存中Cache命中率较低,等于间接减少了可用内存。
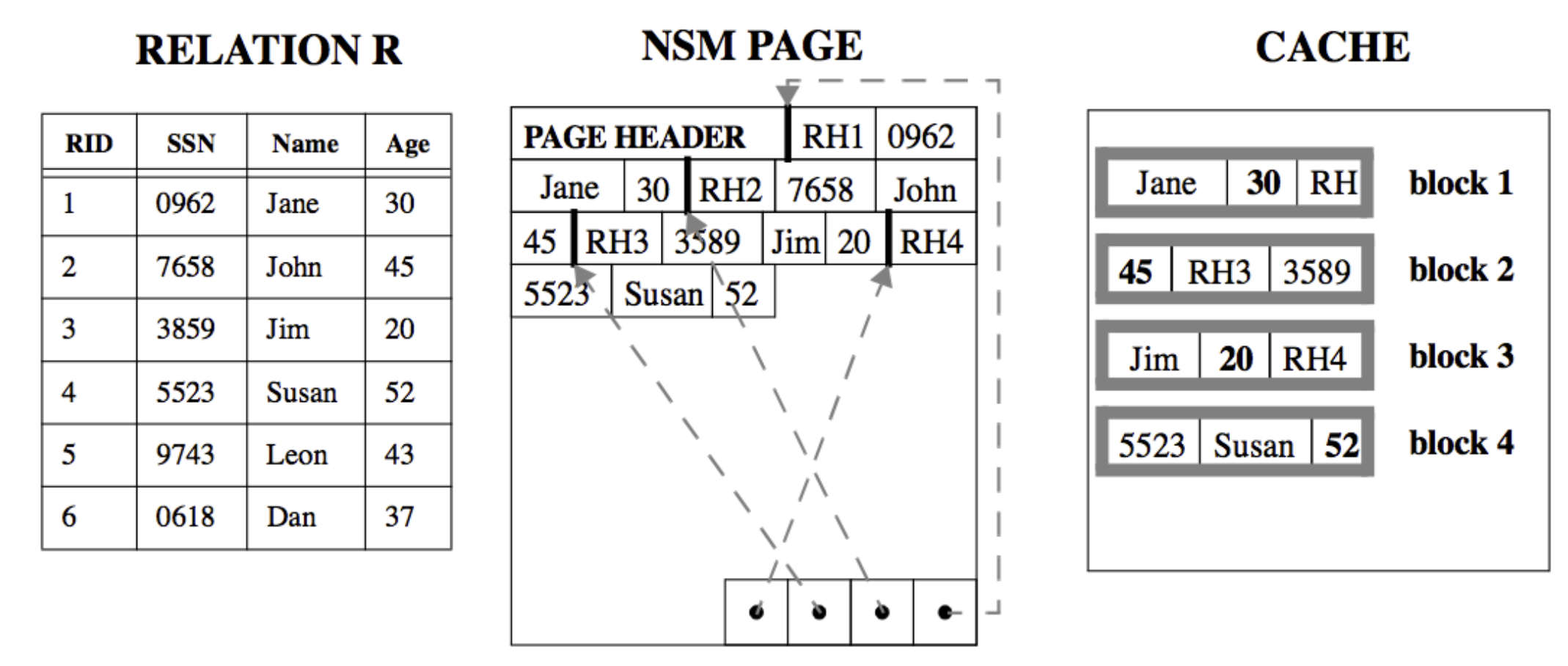 因此几乎所有的OLAP数据库都采用列存的方式,数据按列组织,行存一页可能只有10条record,但是列存一页就可能有1000条record的相同列,同一个Page中就能存放大量相同的列,如果只读取某一列,效率非常高,cache命中率也更高。
因此几乎所有的OLAP数据库都采用列存的方式,数据按列组织,行存一页可能只有10条record,但是列存一页就可能有1000条record的相同列,同一个Page中就能存放大量相同的列,如果只读取某一列,效率非常高,cache命中率也更高。
Spanner即非原始的行存,又非列存,它使用一种名为PAX的结构,行列混存:
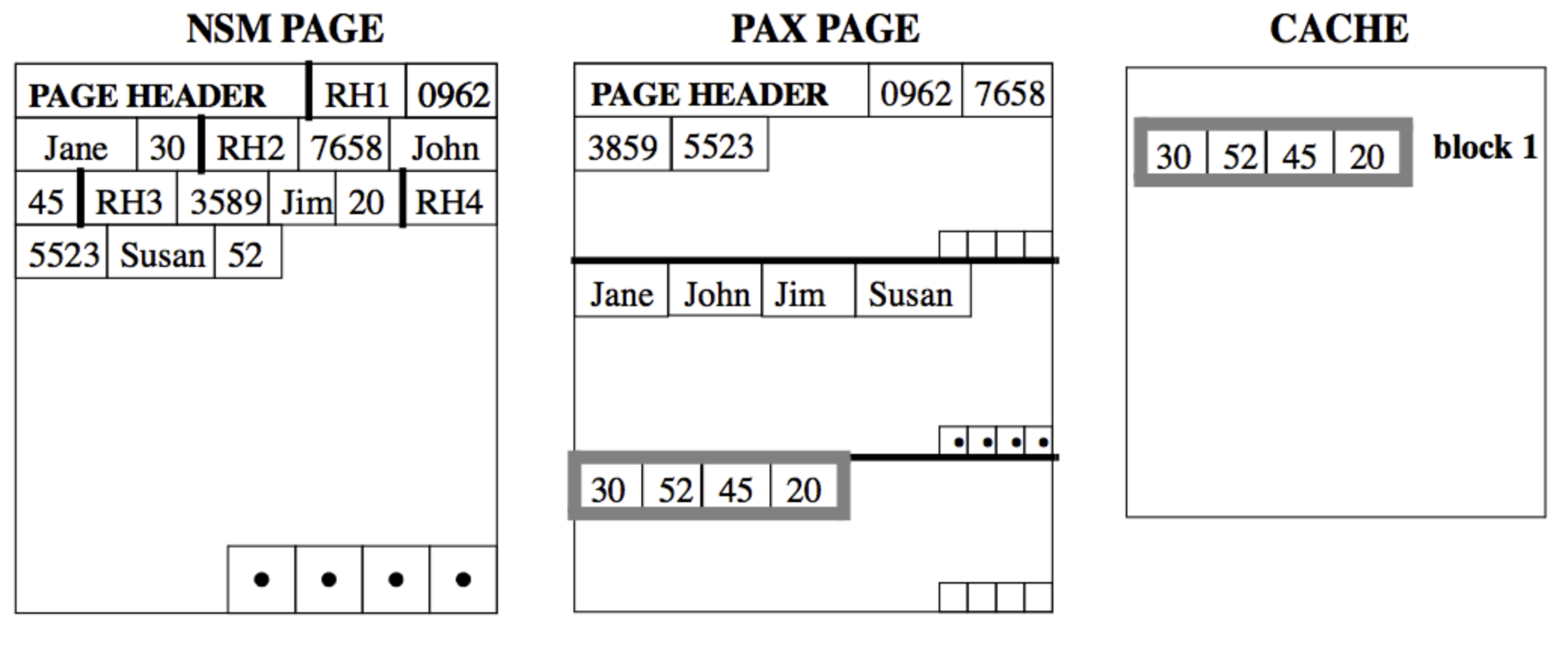 PAX将每一页分为多个mini page,每个mini page存储特定的列,因此只需要查询特定的列时,只需要读取少数的mini page,而不需要将整个Page都读入内存,如果需要查询整条数据,也可以直接将整个Page读入内存。
PAX将每一页分为多个mini page,每个mini page存储特定的列,因此只需要查询特定的列时,只需要读取少数的mini page,而不需要将整个Page都读入内存,如果需要查询整条数据,也可以直接将整个Page读入内存。
总结
Spanner本质上是一个Key-Value数据库,使用LSM-Tree提升写入吞吐量,数据在页(Page)中为PAX行列混存结构,因此能够进行OLTP还适合进行轻量OLAP。
参考资料
Data Page Layouts for Relational Databases on Deep Memory Hierarchies